A story about distance, decisions, and deeply confused robots
I, as a rule, become deeply entrenched in annoying systems.
I learned JavaScript and got obsessed with what I could make it do through coercion.
I learned cap table accounting and wanted to see what changes destabilized the math.
I started talking to chatbots and immediately tried to make them hallucinate.
I have an unhealthy obsession with teaching machines how to solve Sudoku.
Some of the first Python I ever wrote was code trying to solve Sudoku — and then code trying to explain its logic back to a human.
I have a webpage that ambiently solves a Sudoku puzzle with color. It always comes to the same solution, but I like to watch it the way some people watch a yule log.
I want an AI that can think about Sudoku.
Now here’s where these two ideas converge.
I don’t really know how to program AI agents.
I know how to do depth-first and breadth-first search.
I can write a greedy algorithm.
I can brute-force.
I’m even decent at turning complex human logic into rules a computer can understand.
But I don’t understand how an AI learns to make decisions.
So, naturally, I decided to poke an AI about it.
I asked ChatGPT if it could teach me how to be a reinforcement learning agent. It said yes — and immediately started vomiting code. I asked it to stop and just tell me the idea.
We decided to build Gridworld.
A simple one.
A little dude wandering around an empty room.
Then came the "but why?" phase:
"You said we needed numpy, why?"
Great question — and you're right to challenge this early. You don’t strictly need numpy for Gridworld — it's just a convenience.
"Why doesn’t the agent ask the env what actions are valid instead of taking bad ones?"
In standard RL setups (like OpenAI Gym), the agent chooses from a fixed action space, valid or not.
"Won’t this only work if the maze never changes?"
Yes — exactly. You've nailed a key limitation of basic Q-learning.
And, of course, the non-sequiturs began:
"What if the world was round O.O"
- Agents can’t bump into walls — but they can go in circles
- Makes pathfinding more interesting (you can "warp" to the other side)
- Reduces dead-ends or boundaries
- Could simulate things like planet surface navigation
This is how I learn: by being annoying.
And, because of how memory works, I can bounce off the walls just like the little robot insists on doing.
So, as you do, I built a little robot friend, put him in an empty room, and told him to get to the other side.
. . . . .
. A . . .
. . . . G
Step: 3 of 100
Total Reward: -3
. . . . .
. . . . .
. A . . G
Step: 4 of 100
Total Reward: -4
For clarity: this robot isn't learning. It's just using Manhattan distance.
This makes the room solved, which is interesting — because now we can measure what AI is actually adding compared to known logic.
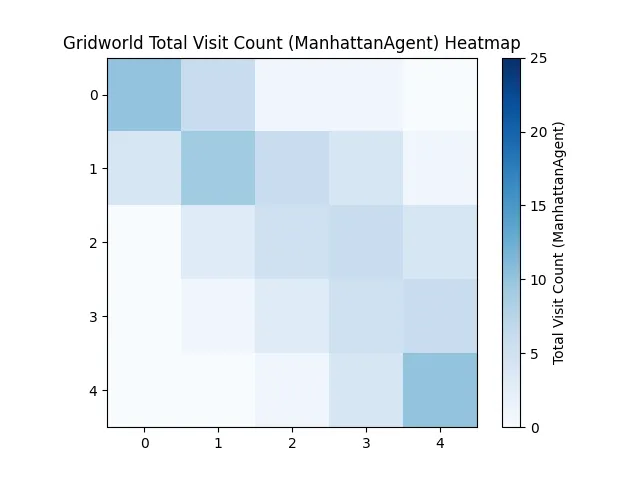
Because it's a non-deterministic best path (any shortest path is equally valid), the actual routes the robots take vary a lot — especially far from the start or end. On a heatmap, this makes things look a little washed out.
Let’s run the AI.
No hints. Just: "get to the end."
And it really struggles.
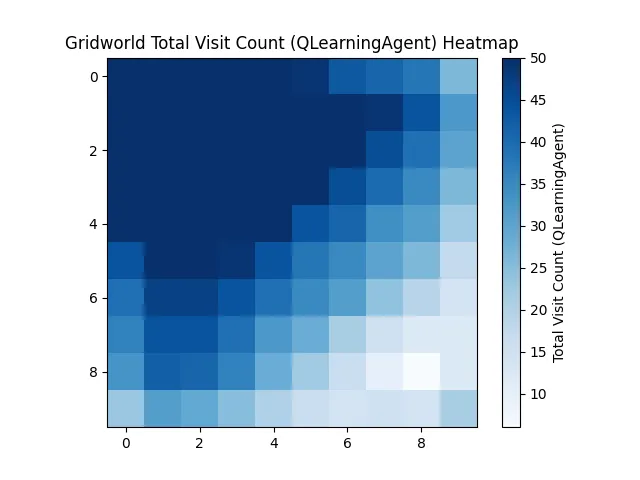
That’s because it doesn’t know where the goal is. Or what the reward is. Or how to get there. It has 100 steps to figure out an 18-step problem.
Average Reward: -55.7
Reached Goal Count: 21/100
Average Steps: 83.84
Eventually, it stumbles onto the goal. And starts to remember.
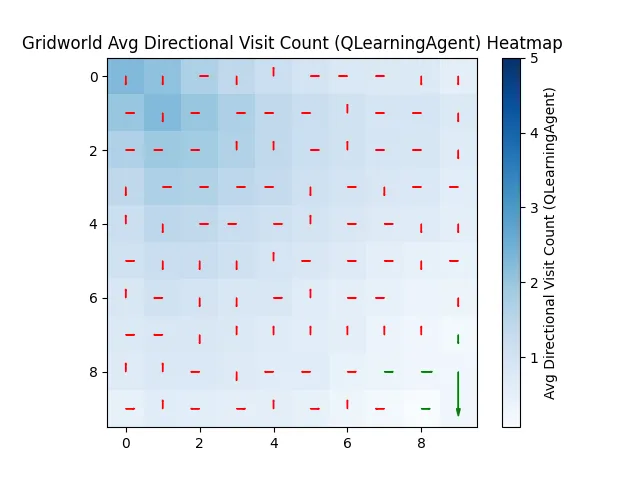
But the learning is painful. It struggles to propagate back what it learned. Some runs get worse before they get better.
| Iter | Avg Reward | Max | Min | Steps | Reached Goal % |
|---|---|---|---|---|---|
| 1–3 | -154.00 | -136 | -181 | 100.00 | 0.0% |
| 25–27 | -10.00 | 60 | -100 | 73.67 | 66.7% |
| 43–45 | -25.33 | 64 | -136 | 71.00 | 66.7% |
It’s not having a great day for a while. Even in the later attempts, it struggles to pull the reward signal all the way back through what it knows.
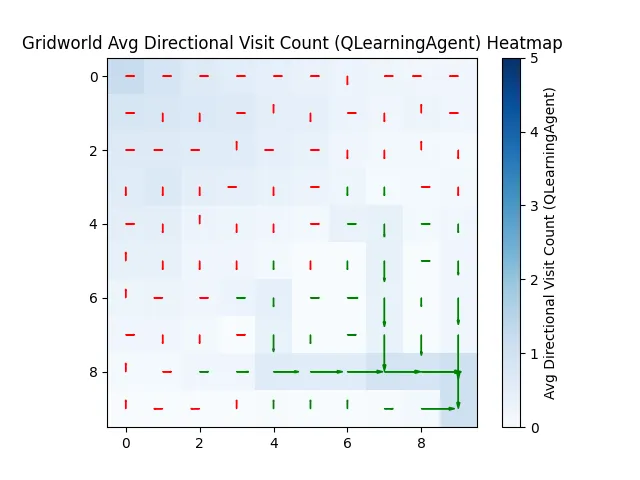
By 450 runs, it's confident. But committed to a specific path.
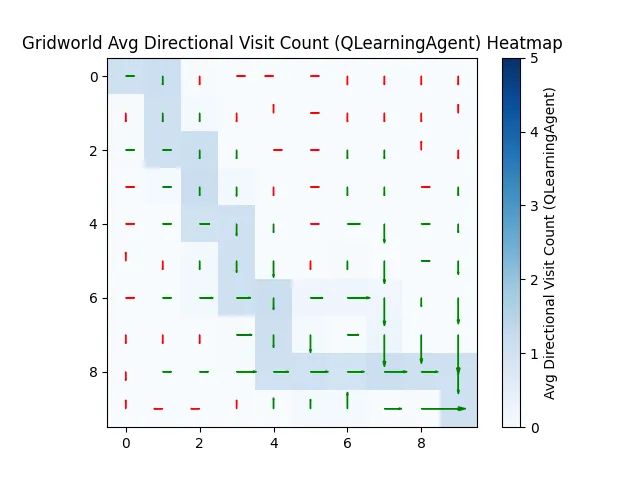
Unlike Manhattan, which happily tries all paths, our AI buddy picks one and sticks with it.
So what does this mean?
Honestly, not much — if you just want to cross a room, walk across it.
But for AI, it teaches us more about the robot than the task:
This robot can get precious about the answer they found (not unlike staff engineers).
This robot works backward from a known solution, while humans are better at working toward an unknown.
What I learned — that is not the robot’s fault.
When your robot is running your code thousands of times and not asking for permission, it's easy to miss when you’ve made a mistake.
The best way to find that mistake is to attempt to break it. Exploratory testing for the win.
I gave it an unsolvable maze.
Not enough steps to reach the goal.
It learned the wrong thing: that dying in a certain spot was good. And then every robot tried to die in that spot.
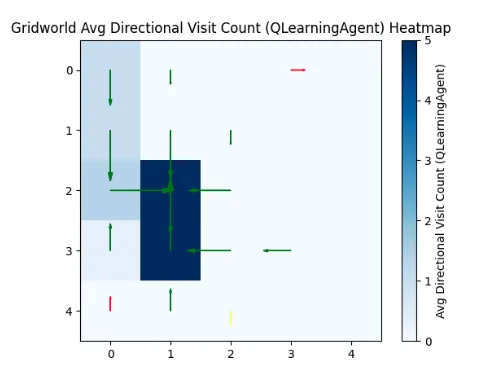
It’s not the robot’s fault.
It’s mine.
I taught it that running marathons was good.