Looking for the Number 4 Inside the Black Box
As I believe is clear, I'm quite interested in why AI does what it does. Some of that interest leads me to watching lectures.
In one lecture on image classification with neural networks, the instructor said something like: “In the first layer, it will focus on small groups of pixels to find lines and edges.”
That sounded super interesting, so I decided to try it out myself. I ran the code, and what I found was this:
Which I want to be super clear about: that image shows the most focused pixel in that training run. So, not very focused at all.
To be fair, the model works fantastically. It’s a really solid toy example—it gets the right answer 99.99% of the time or something wild.
But I thought what happened here is that the conversion into a toy model, with less images and a smaller network, actually broke the core idea the lecture was trying to show. The model works, but it doesn't work in that way.
(It turns out I was wrong about this. The problem wasn't the model. It was the lecture. The idea that the first layer focuses on small regions and then builds up is true, but it applies to a different kind of architecture. I didn't figure that out until much later. And I'm not actually going to address it here, because I decided to instead see what I could make this one do in 3 hours.)
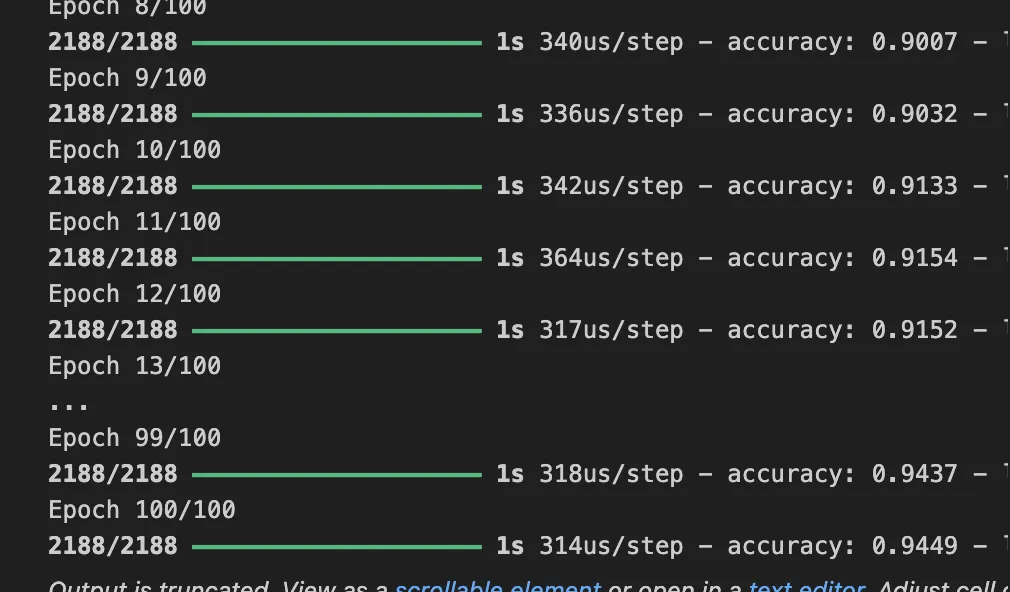
And I really wanted to see it focus on edges. So I added regularization to promote sparsity.
model = Sequential(
[
tf.keras.Input(shape=(400,)), #specify input size
### START CODE HERE ###
Dense(
units=25,
activation="sigmoid",
kernel_regularizer=regularizers.l1(1e-5)
),
Dense(
units=15,
activation="sigmoid",
kernel_regularizer=regularizers.l1(1e-5)
),
Dense(
units=1,
activation="sigmoid",
kernel_regularizer=regularizers.l1(1e-5)
)
### END CODE HERE ###
], name = "my_model"
)
I got this:
Which I would say is starting to look focused, but still has a bit of an attention split. Again, this is the most focused neuron.
Then I started to wonder, what if the problem is just too easy? A lot of these neurons might be lighting up because they don't matter. So I swapped from a dataset of 1000 zeros and ones to the full MNIST set, 'mnist_784'.
And you know you can't just do that apparently...
So I added a softmax:
model = Sequential(
[
tf.keras.Input(shape=(400,)),
Dense(
units=25,
activation="sigmoid",
# kernel_regularizer=regularizers.l1(1e-5)
),
Dense(
units=15,
activation="sigmoid",
),
Dense(
units=10,
activation="softmax",
)
], name = "my_model"
)
Also I updated the compile
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer='adam',
metrics=['accuracy']
)
That all worked but wasn't very accurate.
It seemed a little short on friends. But don't worry we can build them.
model = Sequential(
[
tf.keras.Input(shape=(400,)),
Dense(
units=128,
activation="relu",
# kernel_regularizer=regularizers.l1(1e-5)
),
Dense(
units=64,
activation="relu",
# kernel_regularizer=regularizers.l1(1e-5)
),
Dense(
units=10,
activation="softmax",
# kernel_regularizer=regularizers.l1(1e-5)
)
], name = "my_model"
)
That actually is pretty interesting. But does seem to be falling a little bit into an overfit:
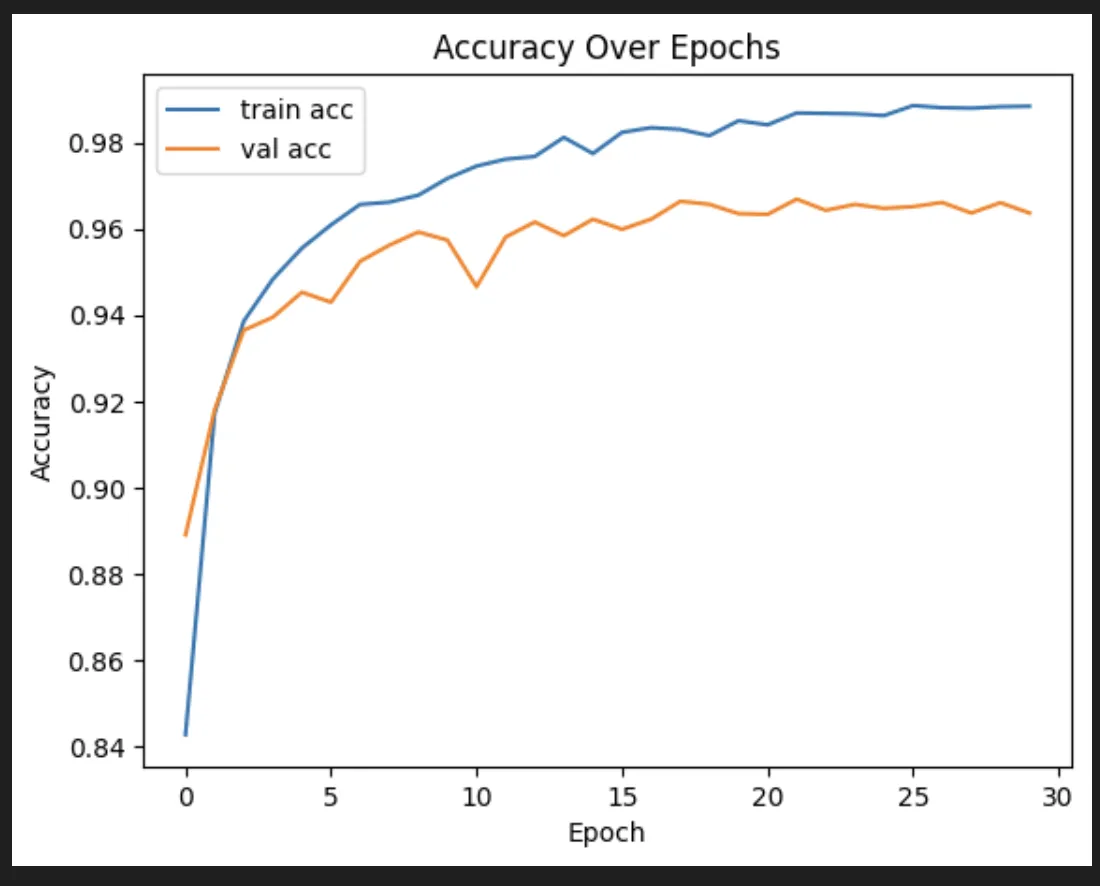
So we tried some stuff. First, we added some dropout, which basically just throws out a portion of the neurons after each layer. That was actually hugely helpful for accuracy. It was less great for the quality of the training itself, unfortunately.
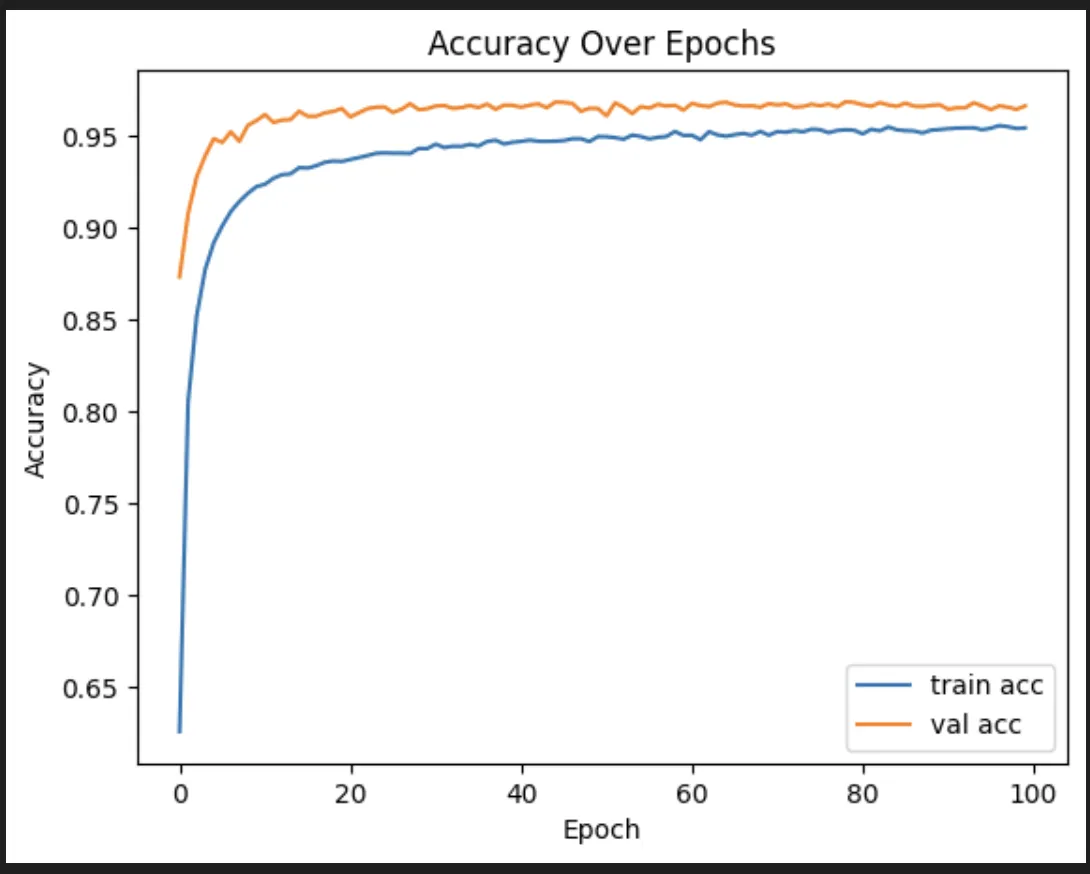
I also added early stop, which is basically a short circuit that stops training once the validation set stops improving.
early_stop = EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True
)
history = model.fit(
X,y,
epochs=100,
callbacks=[tracker, early_stop],
validation_split=0.2,
shuffle=True,
)
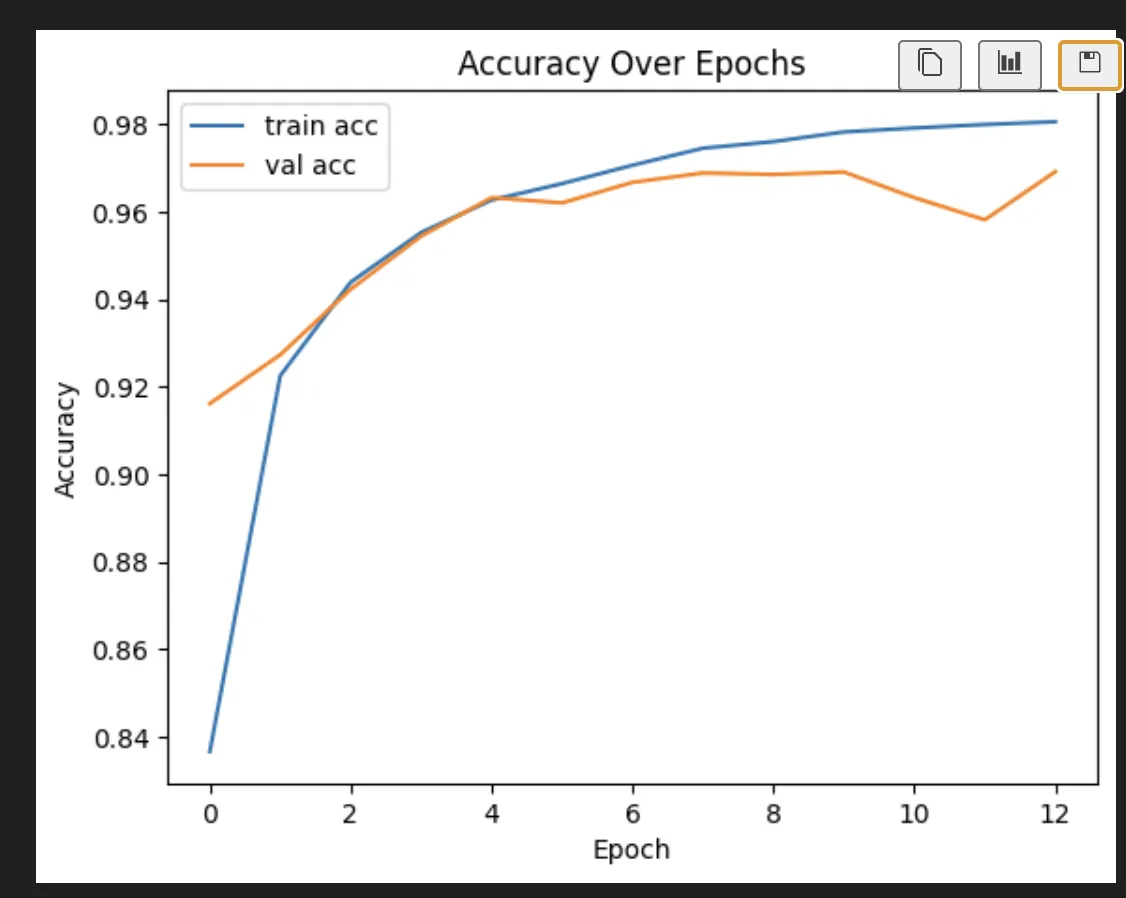
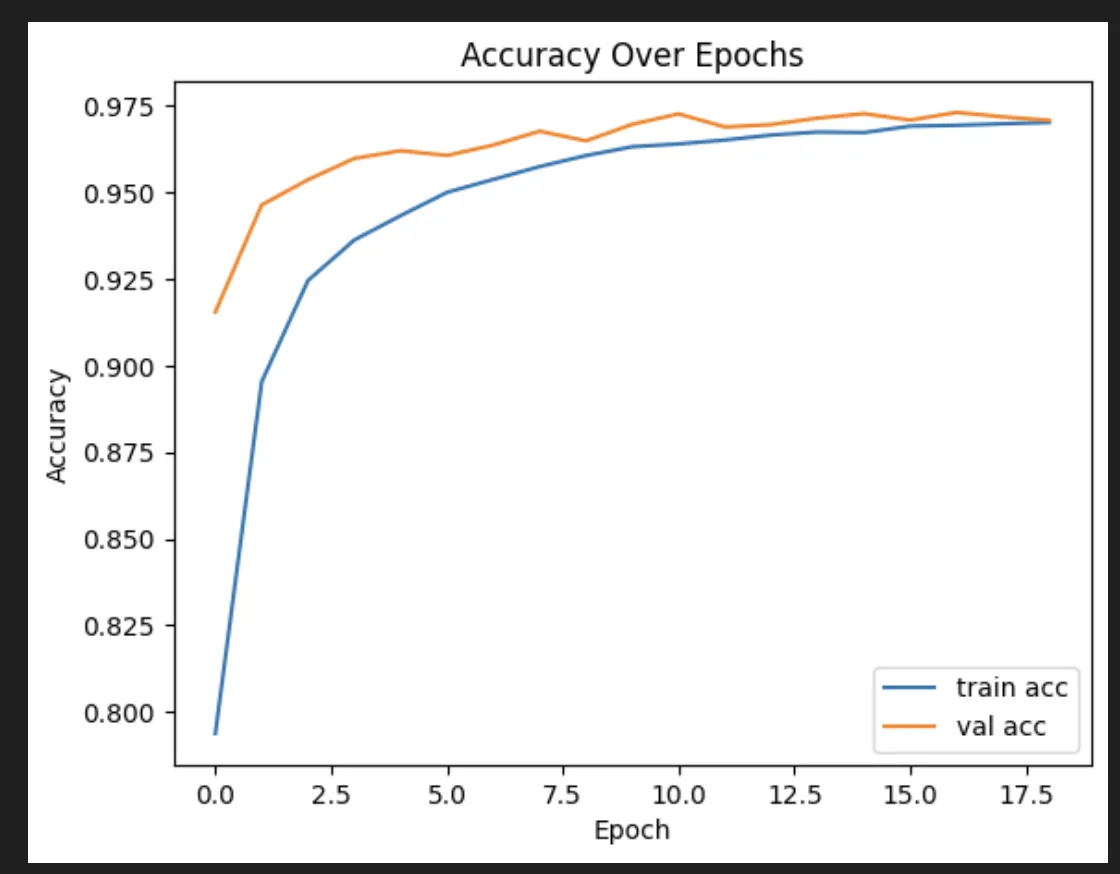
I also tried dropping in some regularizers with and without dropout.
Only regularizers:
Regularizers and dropout:
Only dropout:
Dropout turned out to be by far the most effective change, though I ended up using a much less aggressive version than the AI friend I was discussing it with recommended.
I also tried adding batch normalization. I have no idea how actual intelligent humans decide which of the hundred available techniques to use. I’m mostly just poking it until it looks like it works.
We have landed here:
model = Sequential(
[
tf.keras.Input(shape=(400,)),
Dense(
units=128,
activation="relu",
),
BatchNormalization(),
Dropout(0.1),
Dense(
units=64,
activation="relu",
),
BatchNormalization(),
Dropout(0.05),
Dense(
units=10,
activation="softmax",
)
], name = "my_model"
)
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
metrics=['accuracy']
)
early_stop = EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True
)
history = model.fit(
X,y,
epochs=100,
callbacks=[tracker, early_stop],
validation_split=0.2,
shuffle=True,
)
And I feel like this is the best I can do right now. But, you know, someone smarter could probably do it better.
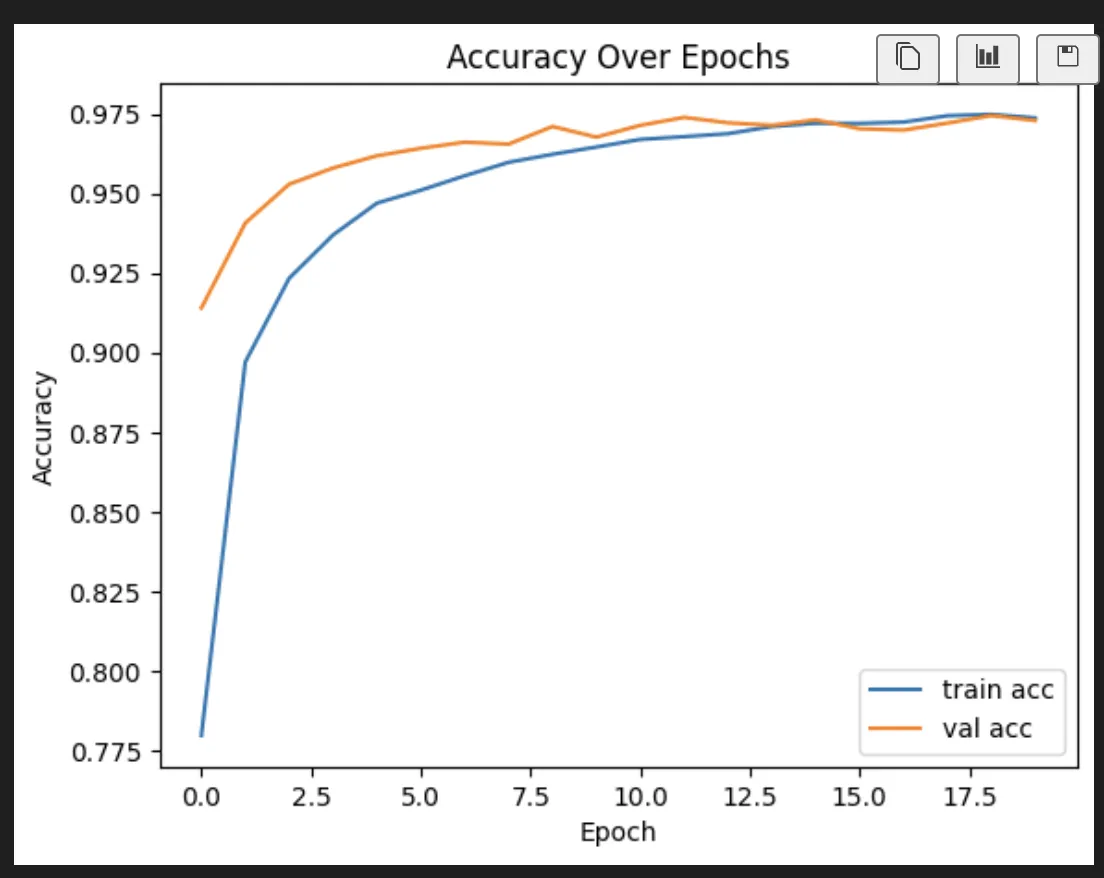
It lands us here:
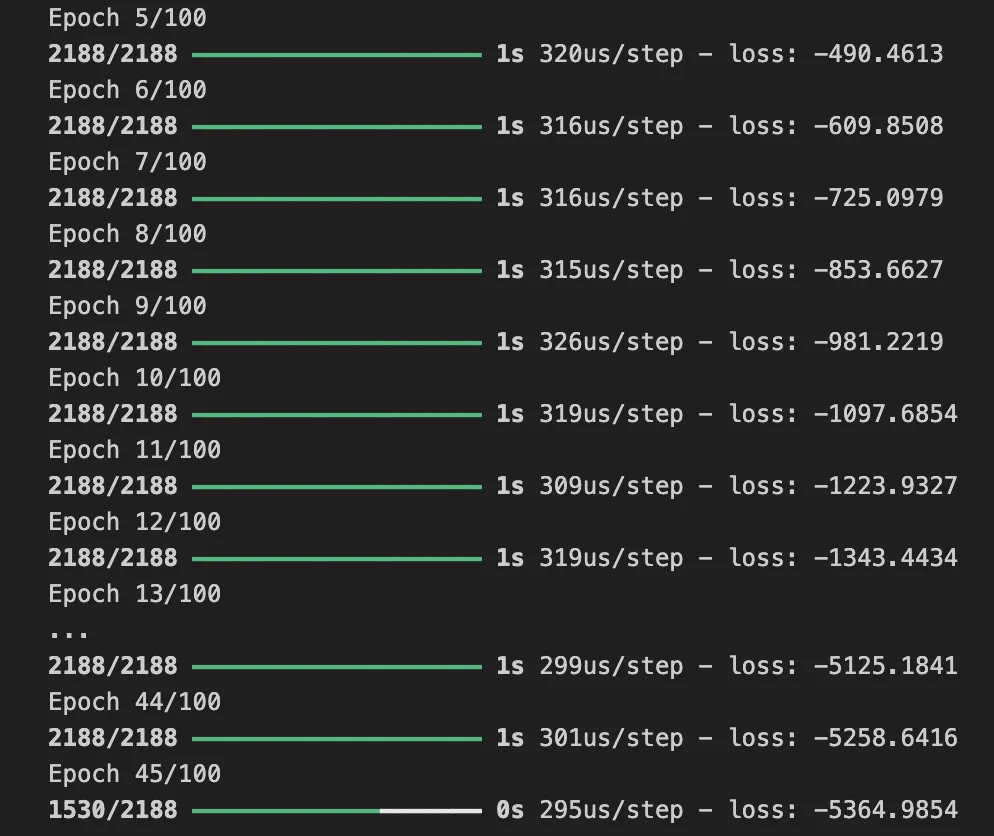
Epoch 18/100
1750/1750 ━━━━━━━━━━━━━━━━━━━━ 1s 639us/step - accuracy: 0.9855 - loss: 0.0429 - val_accuracy: 0.9816 - val_loss: 0.0754
Epoch 19/100
1750/1750 ━━━━━━━━━━━━━━━━━━━━ 1s 650us/step - accuracy: 0.9851 - loss: 0.0433 - val_accuracy: 0.9826 - val_loss: 0.0696
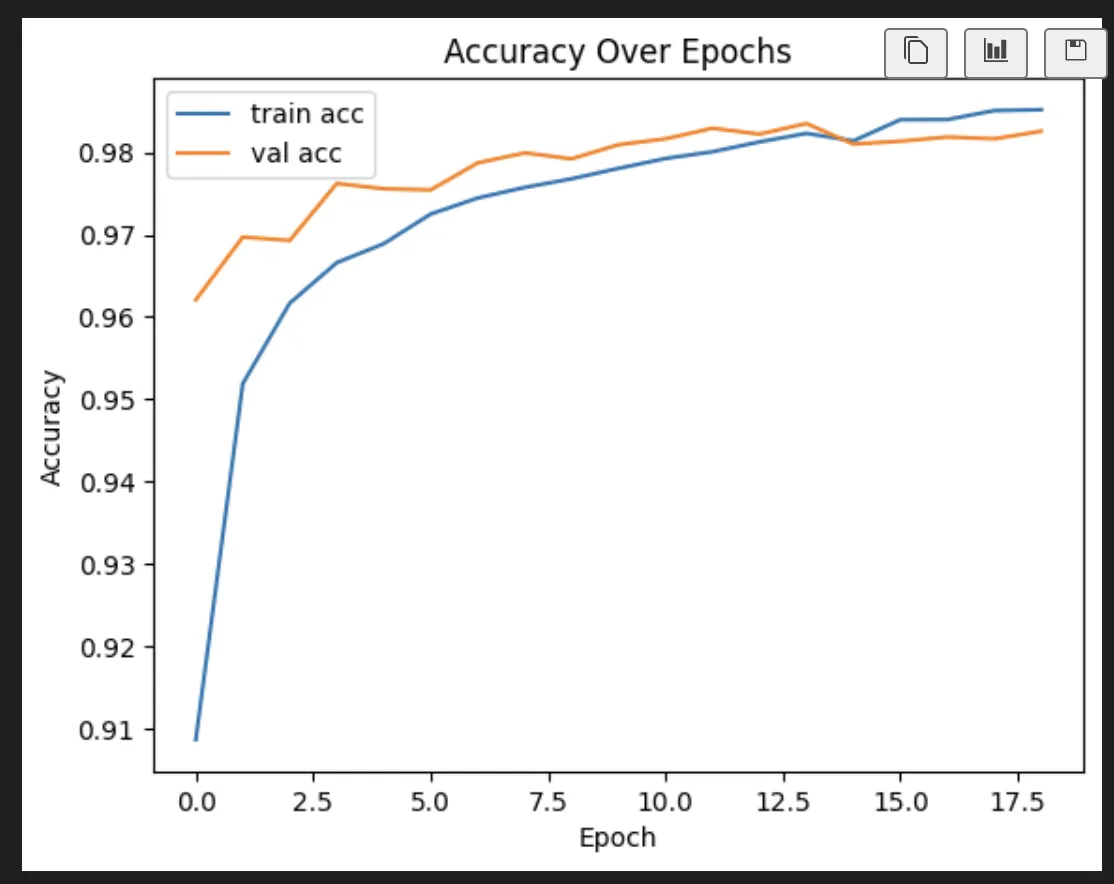
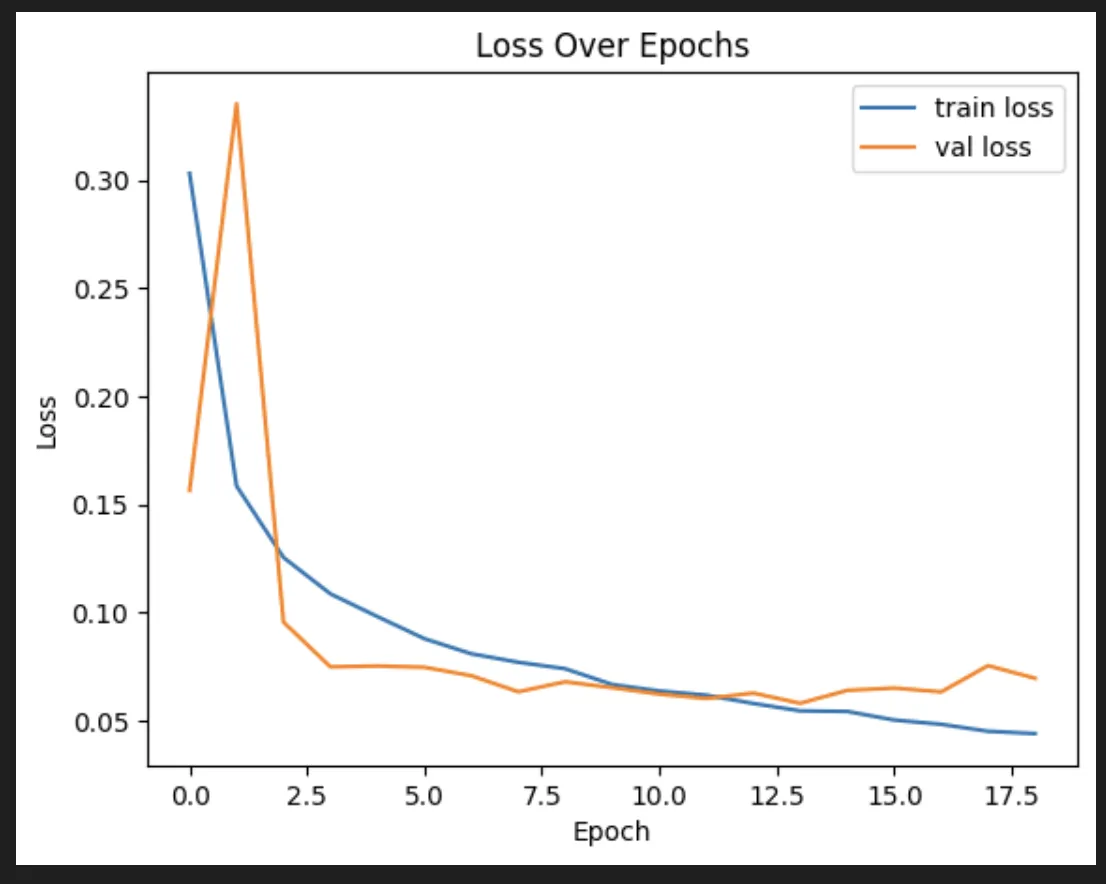

And now we can investigate what it actually did. Which is why we’re all here, right? This shows what happened to a neuron over time.
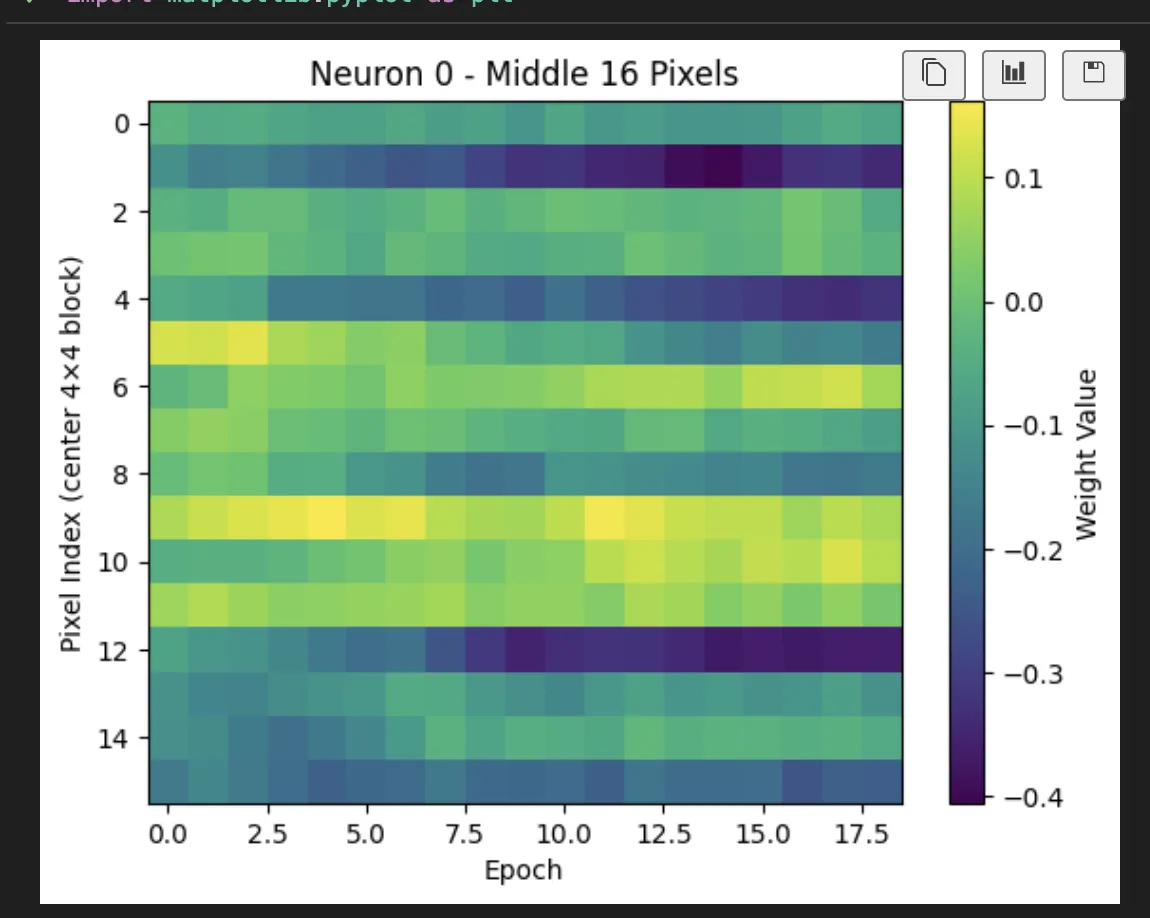
We can also look at how the pixels are changing (up or down which is interesting).
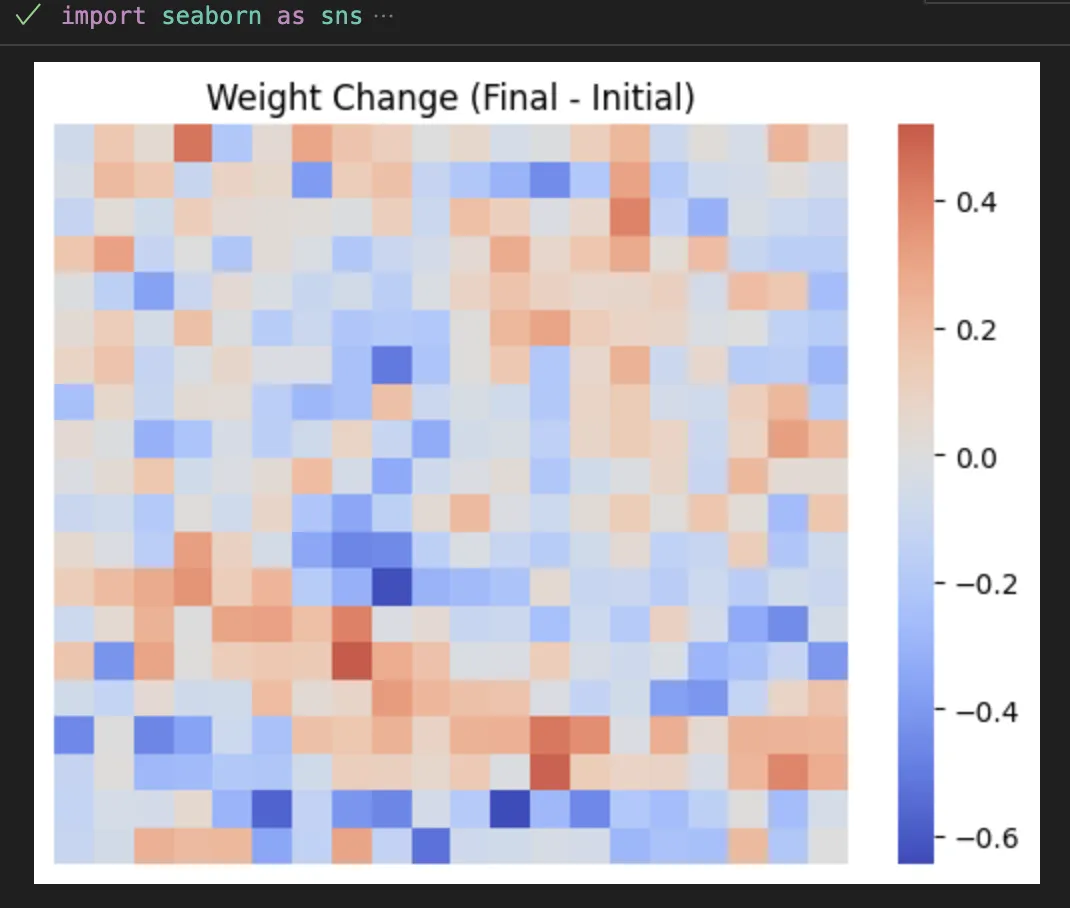
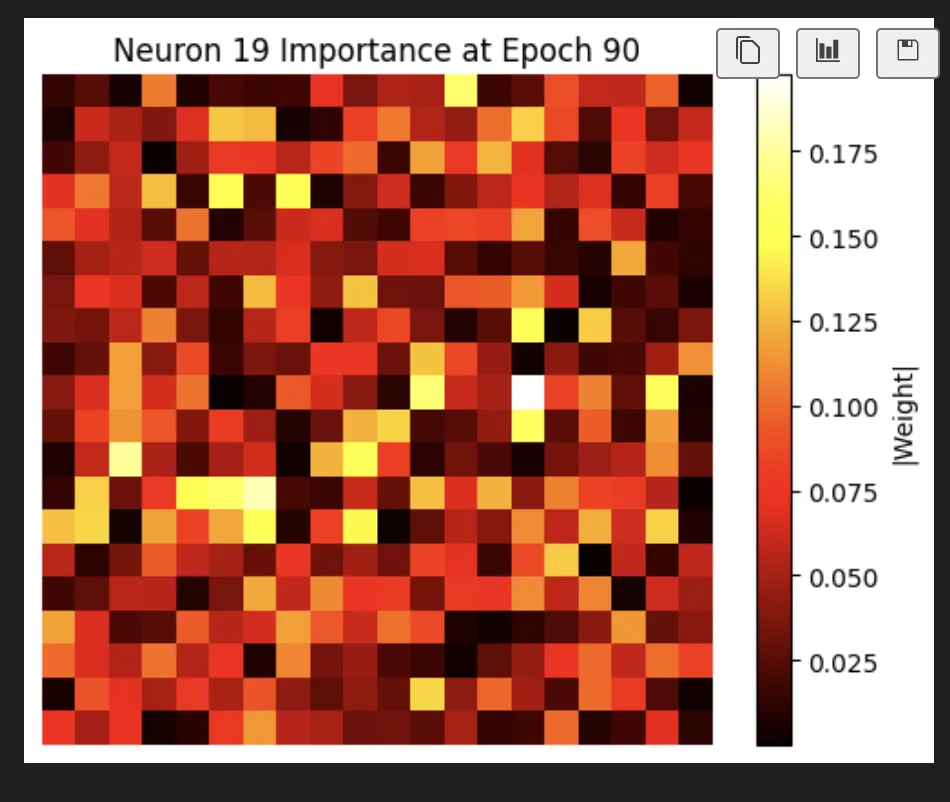
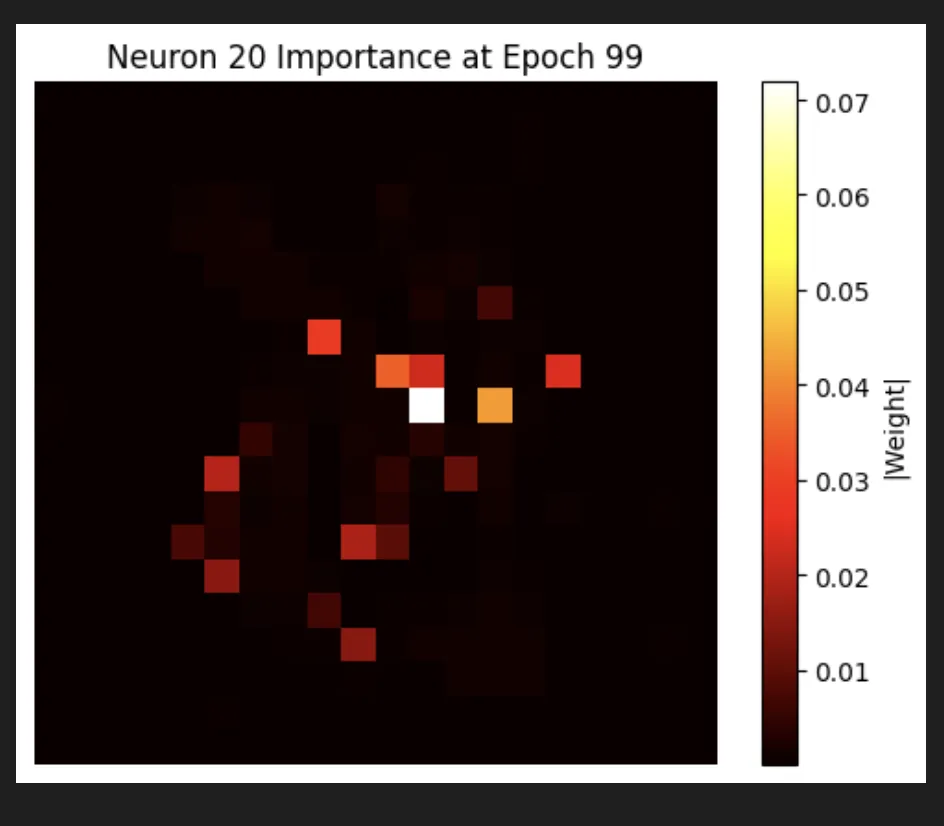
And fantastically, we do actually find that our most focused neuron is truly focused on a small location.
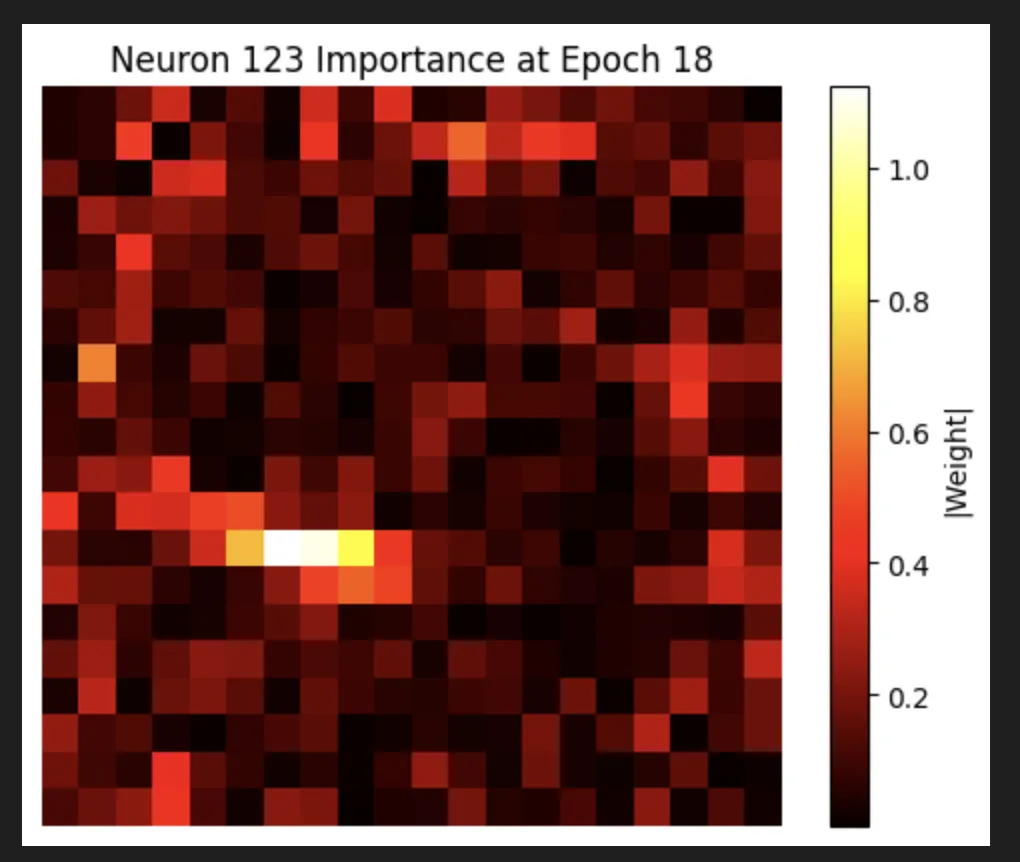
We do actually see some really cool stuff where we have neurons that are very focused on locations that are not close together in space:
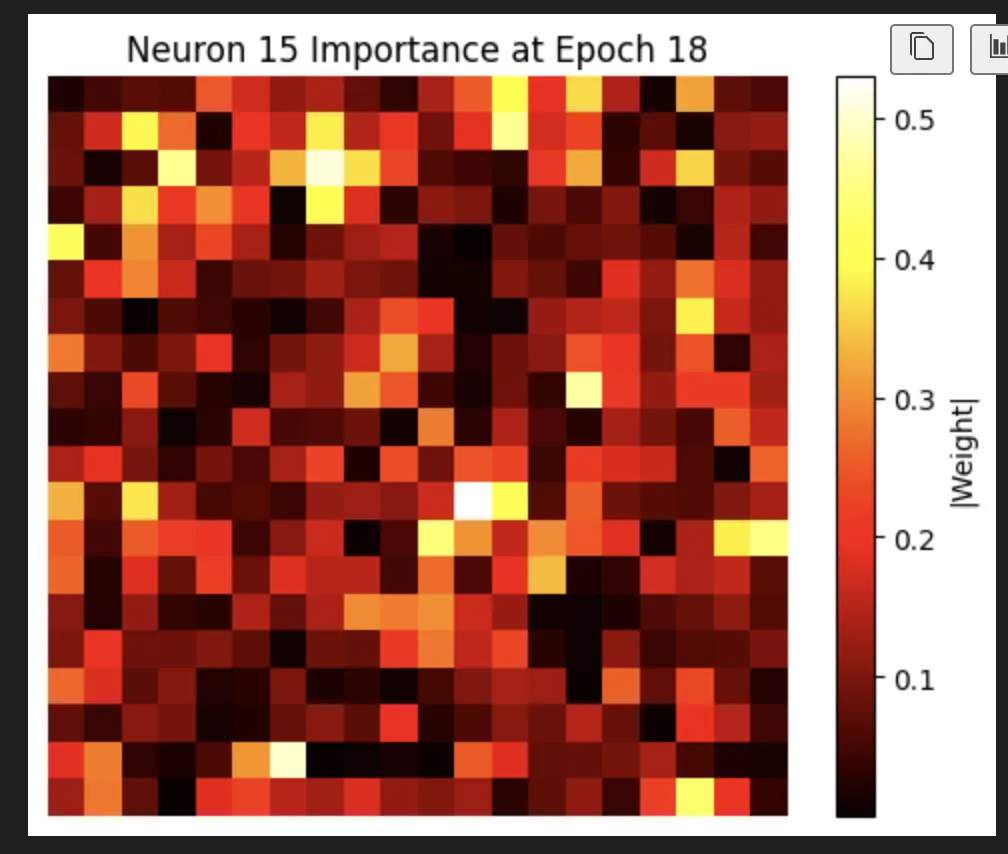
There’s a lot of kind of random noise in the neurons, but there are also some super interesting ones. This one is my favorite. I feel like it’s pretty clearly looking for a 4 (spoilers: I’m wrong again):
There is other stuff we might be able to see like how much do the final values care about the system. If we look at the output node that says "this is a 4" we see:
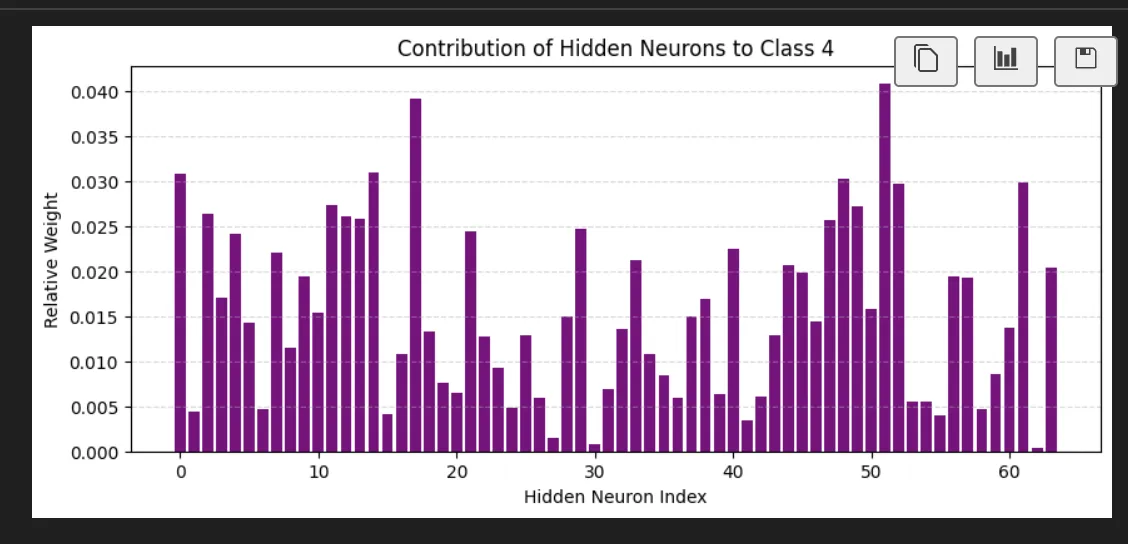
As opposed to the number 1:
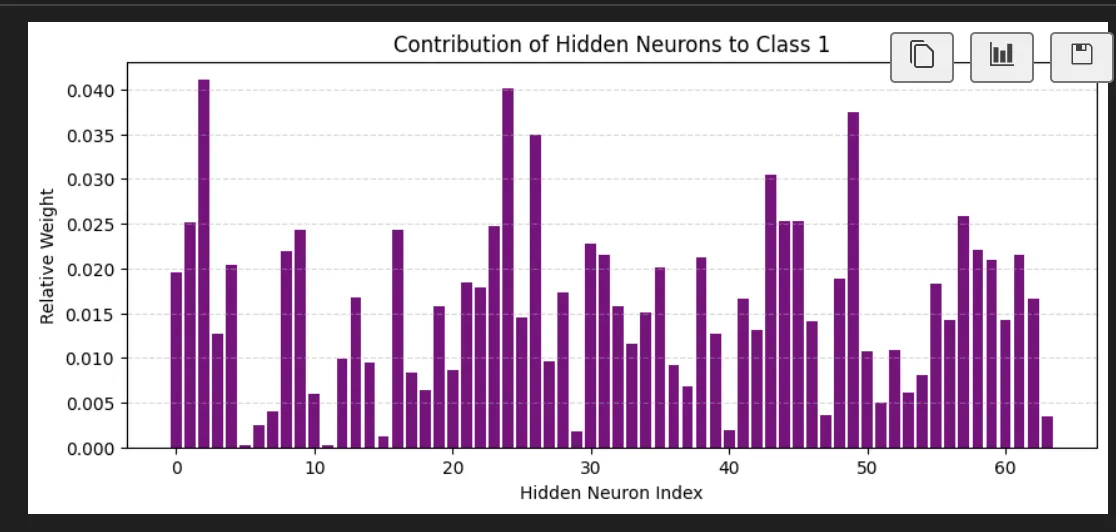
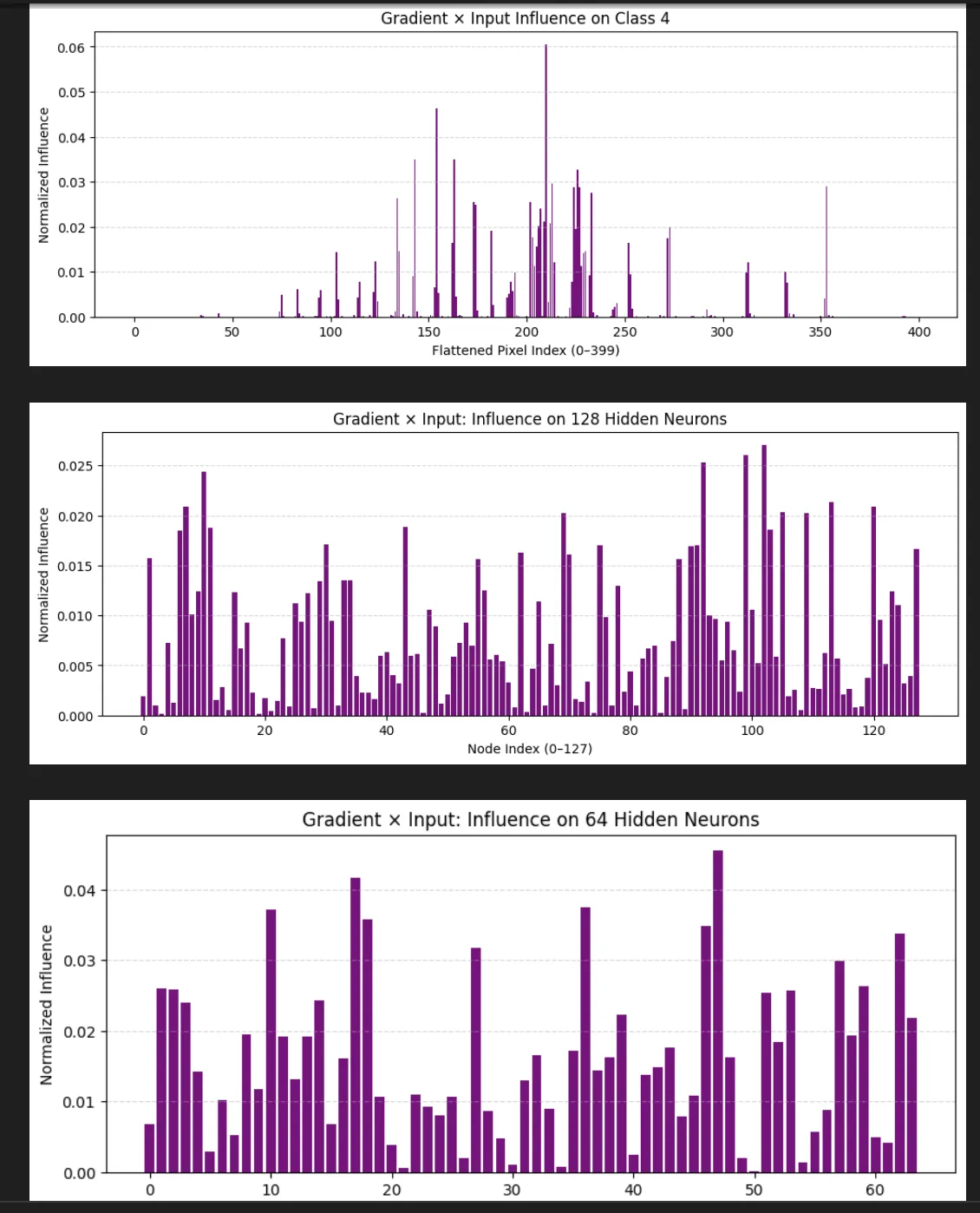
We can then push these values back a level and see on average how much it cares about the neurons in the first layer based on this (the 4 not the 1):
This is super interesting we learned it's favorite neuron in layer 1 is neuron 5. It's actually not that interested in the neuron I identified as definitely part of a 4.
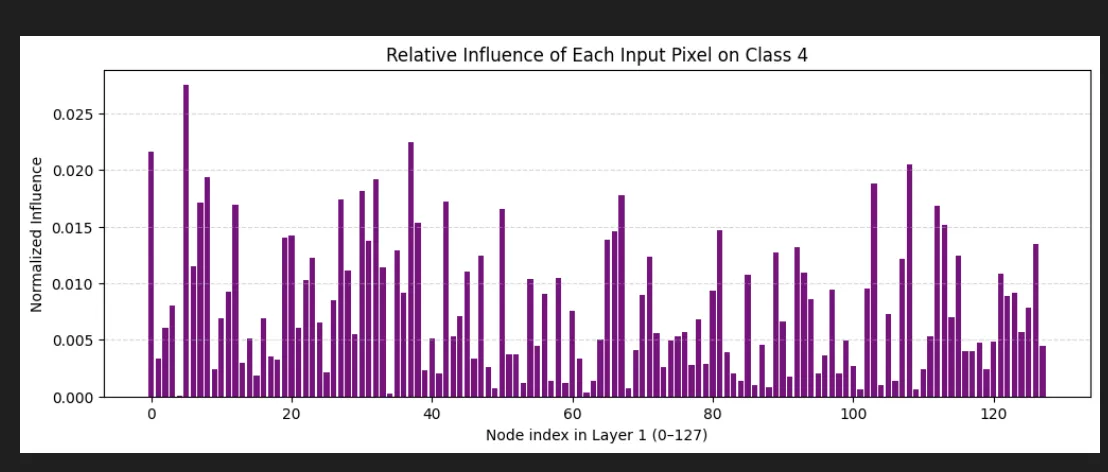
And finally how much it cares about each of the individual input pixel:
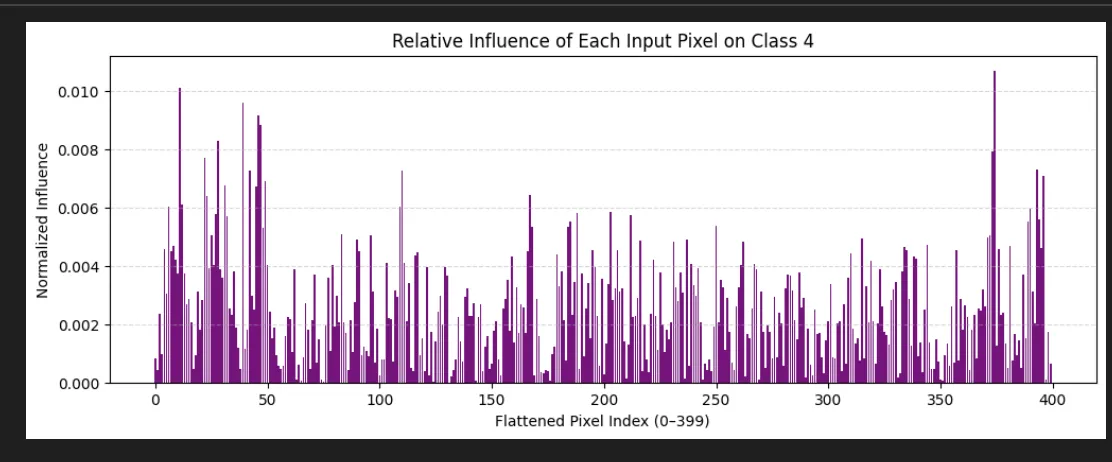
And as a heat map
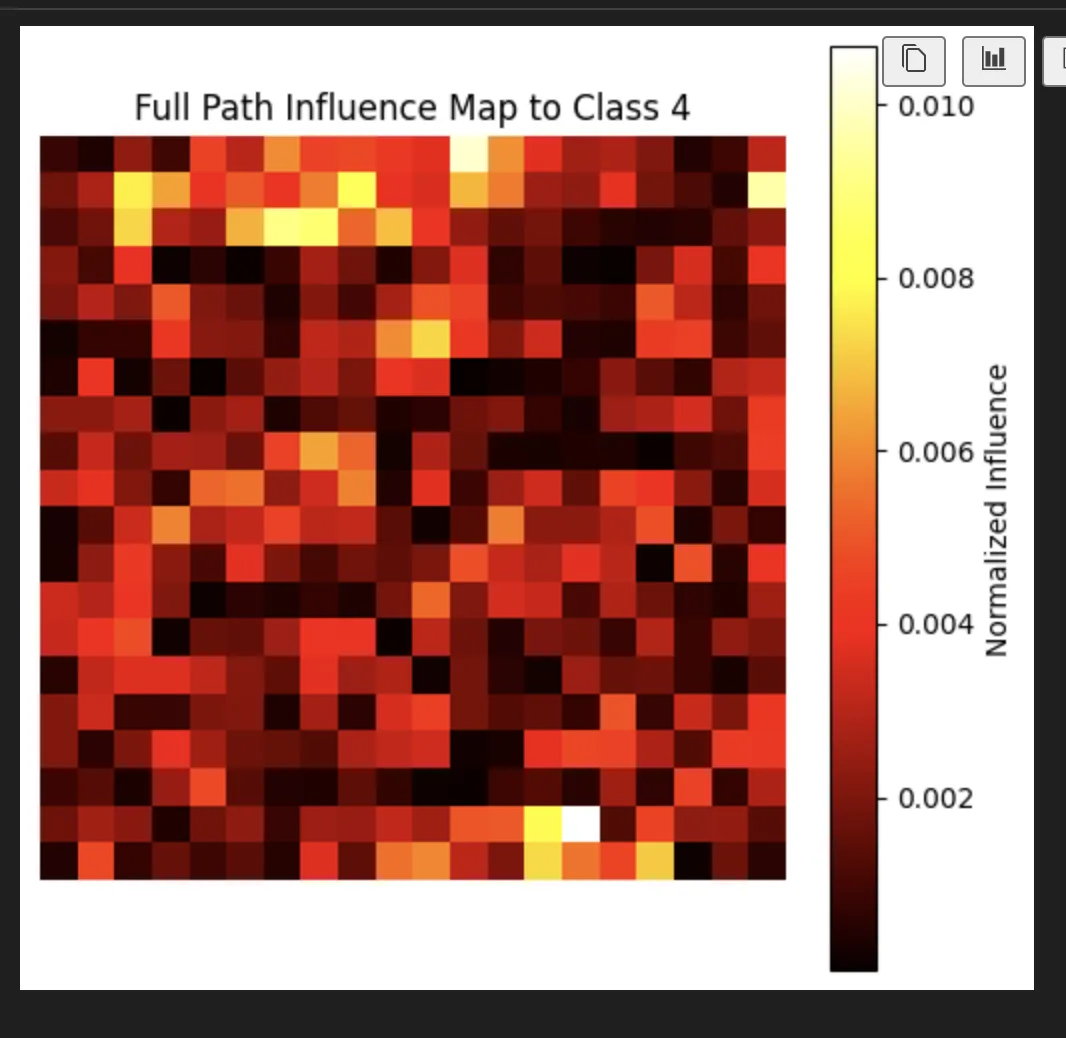
I'm a little sad I was hoping this would like look like a 4.
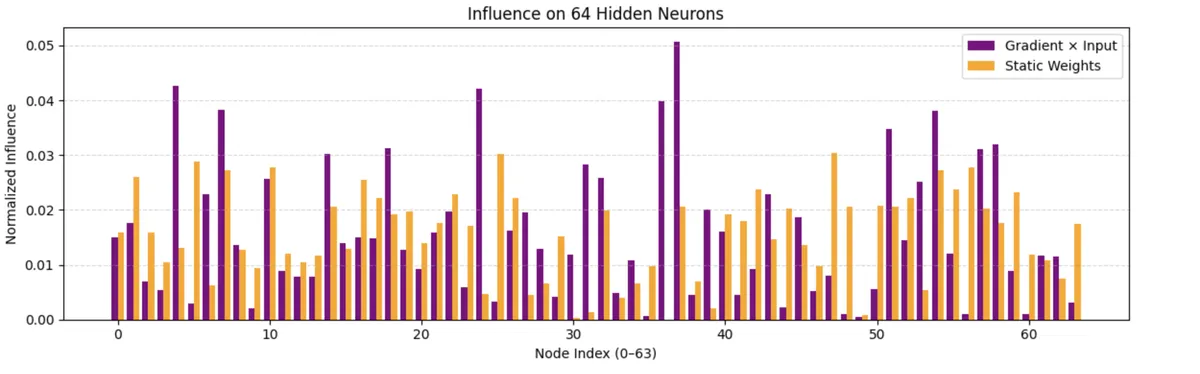
I did run it on an actual example to see how it looked to actually process a real 4:
And I compared a real 4 in the 64 layer to a generalized 4:
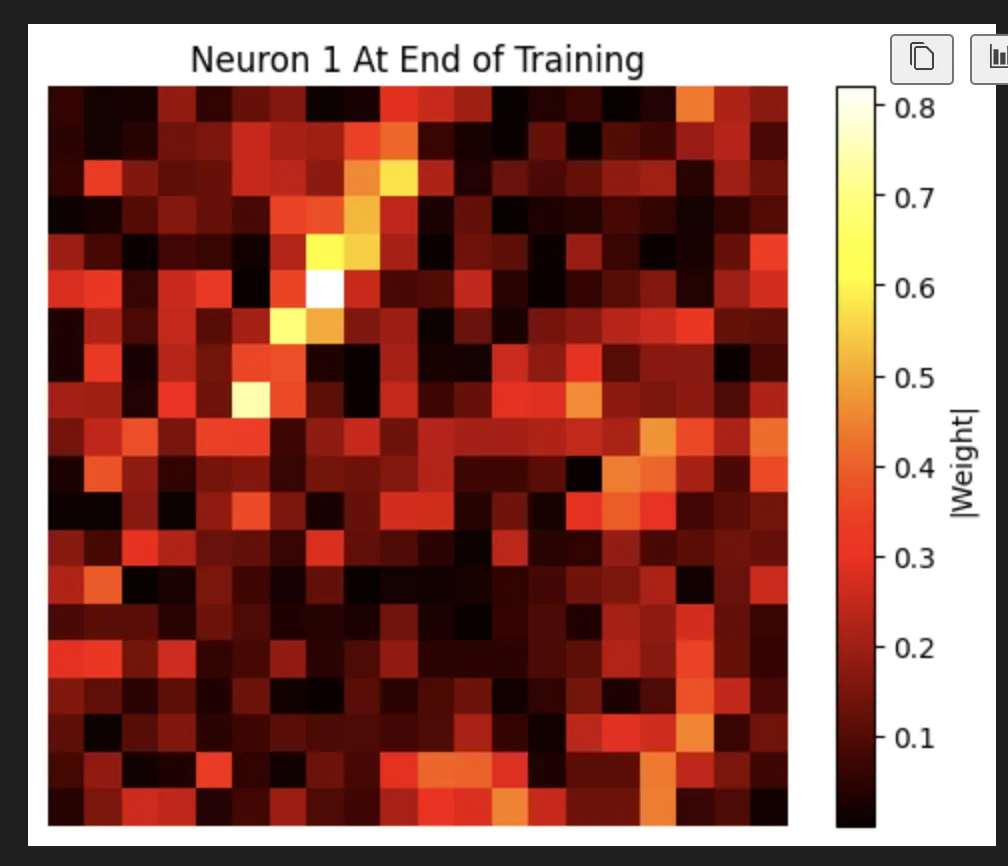
I did (after I had closed VSCode, so this is a unique run of the model) realize that I could find the most differentiated node for a 4 and I found this one:
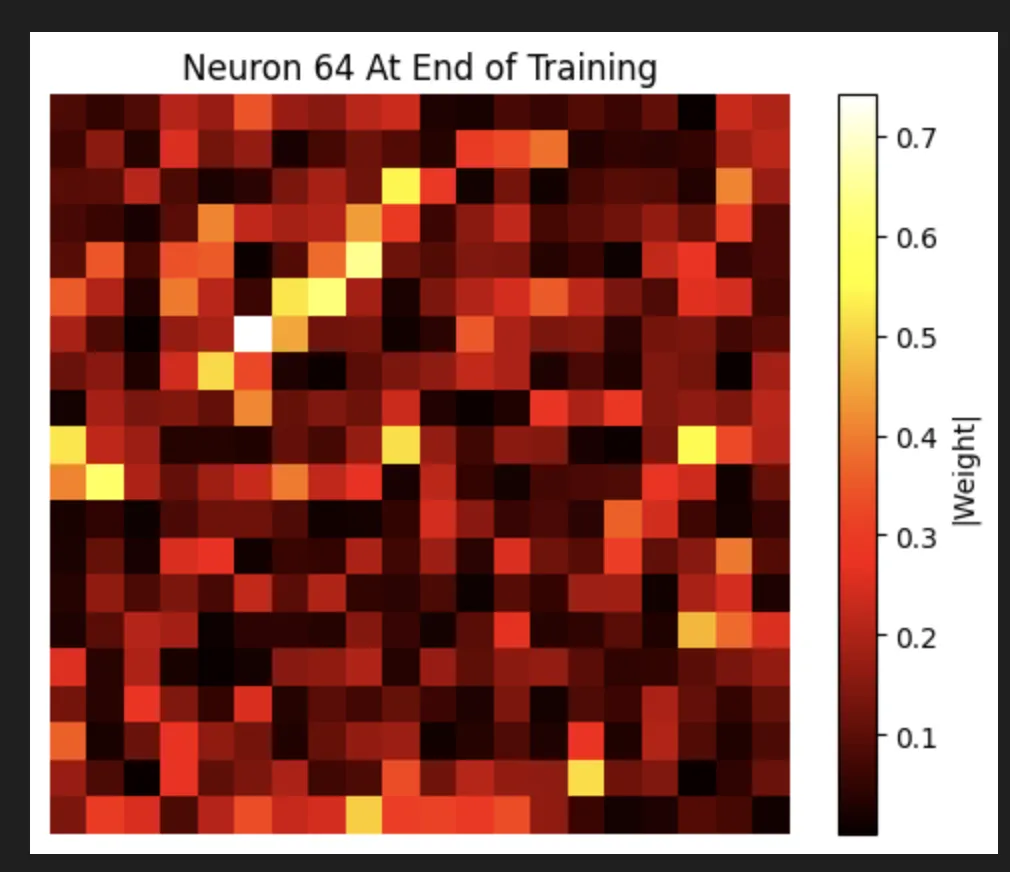
Which is a really fun node just like my favorite node.
I don’t really have anything funny to say about this, and honestly, I don’t fully understand most of what’s happening here, outside of how the algorithm technically works. I could make you a neuron the same way I could make you a NAND gate. But I can’t tell you if the model is good, just like I can’t design a good ALU.